The Revolution that is, TensorFlow!
TensorFlow, a “machine learning system that operates at large scale and in heterogeneous environments”. To put simply, TensorFlow is a system that redefined the scale on which we train and run machine learning models, indescribably more capable than its predecessors. From being able to run large clusters of data sets to running locally on a mobile phone, it’s safe to say TensorFlow was superior for its time. To get a deeper understanding of how TensorFlow performs this magic, we must go back and learn why the Google Brain team, led by Martín Abadi et al, felt like developing such a system.
The Dark Time Before TensorFlow
A long time ago (<2015), running on models far far away, a system known only as DistBelief roamed the machine learning space. DistBelief is the direct predecessor of TensorFlow and is the foundation on which TensorFlow is built. DistBelief uses the prehistoric architecture of parameter servers with stateless worker processes and stateful parameter server processes. This architecture splits its training into two key processes, the training of the data through stateless workers, and the sharing of that data through stateful parameter servers. This would ultimately create a cycle of workers computing gradients and handing them off the server, the server now stores the gradients and keeps the model version up to date.
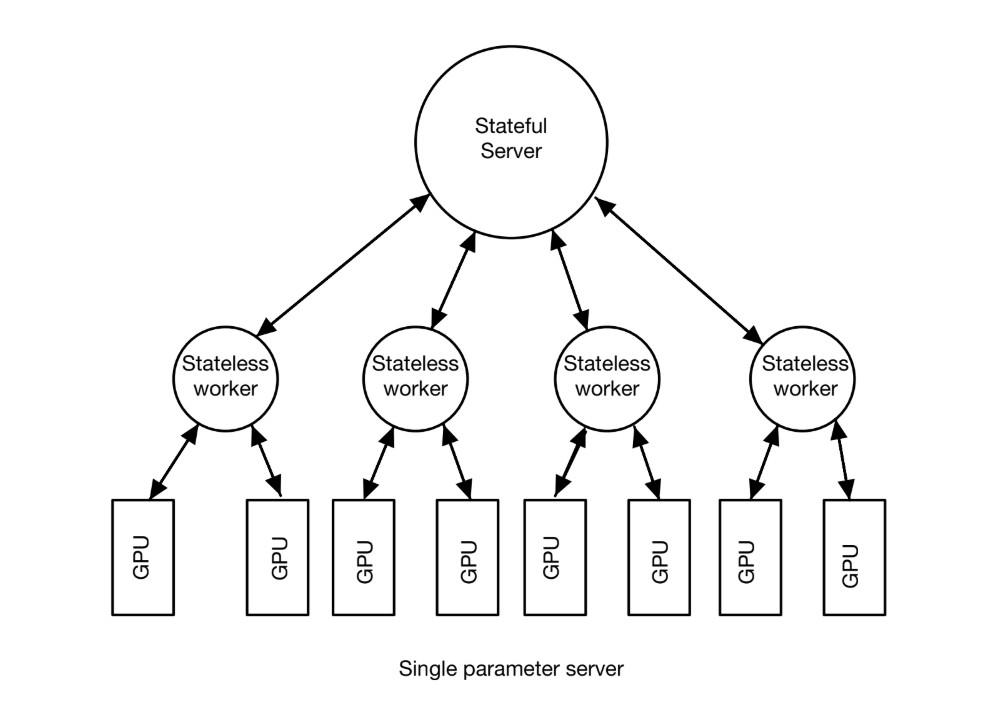
As bland as DistBelief was to an expert’s eye, it’s a little hyperbolic to say it was “broken” or that it “had to change”. Despite this, the developers wanted more. Defining new layers, defining new training algorithms and training them models faster. This is when the Google Brain team had the idea of TensorFlow.
Why Change It If Its Not Broken?
The good old phrase, “if it’s not broken, why fix it?” is not one the Google Brain team** are familiar with. They wanted something more powerful overall, something superior, so they got to work on TensorFlow. Let’s discuss what the team wanted from this new project, TensorFlow. DistBelief had limitations on its computation, the simplest of them being it struggled to define new layer architectures in a model. This was the cause of C++.
See, when DistBelief was being developed, it seemed appropriate for its layer architectures to be implemented using C++ classes. This created a barrier for users defining their own layer architectures (such as softmax classifiers) as they would need to be knowledgeable with C++ to do such actions.
Users often wanted to experiment with different optimisers. At the time, many neural networks used Stochastic Gradient Descent (SGD) which is relatively lackluster in relation to optimisers like SGD with momentum and Adaptive Moment Estimation (ADAM). Strictly speaking changing the optimiser could be done, but it involves modifying the parameter server implementation, which is extremely tedious. This is made harder due to the extremely simple get and put interface in the parameter server, which often require methods to reduce network traffic.
Similarly, the defining of new training algorithms became difficult, mostly due to DistBeliefs workers following a fixed execution pattern. (read parameters, forward pass, backwards pass, calculate gradient). The pattern fails at tasks like running loops, seen in Recurrent Neural Networks (RNN) or when the loss function is computed by an external device in Reinforcement Learning Models. So, now we know why they wanted the revolution, but how will they execute their plan?
Let’s Get To Designing
Now, TensorFlow steps in and prepares to change the game. Simply put, TensorFlow is designed to be more flexible than DistBelief. It used many different principles to allow researchers and users freedom among their models. This new system started with three main design principles, dataflow graphs of primitive operations, Deferred Execution and common abstraction for heterogeneous accelerators. There are some big words in there but I intend to make everything understandable.
Thats begin with dataflow graphs of primitive operators, both DistBelief and TensorFlow use dataflow graphs but TensorFlow ditches the use of complex layers that built its predecessor, but instead uses mathematical operations, such as matrix multiplication or convolution, to comprise nodes within dataflow graphs. This switch to mathematical operators was the switch researchers wanted, now layers can simply be built from combining these operators. This also helps bypass the daunting C++ barrier discussed before. Another positive side effect of these operators is how simple backpropagation became. Crucially, TensorFlow represents matable data and its operations as its own node in dataflow graphs, enabling experimentation with various update rules.
Deferred execution allows TensorFlow to utilise global information about previous computations to optimise its execution phase, ultimately optimising the GPU by issuing kernel instructions without waiting for the intermediate results. This process consists of two phases. The first being to define the program with placeholder data to represent the state, and the second is the execution phase. When the optimised version is pushed and executed on all devices.
The final of these principles, is the common abstraction for heterogeneous accelerators, the core of what TensorFlow uses. Beyond CPUs and GPUs, the Google Brain team developed the TPU (Tensor Processing Unit) specifically with machine learning in mind. This was in an effort to improve the performance per watt, and it did just that. For a device to be compatible for all processing units, TensorFlow creates a common device abstraction. All devices, regardless of its type, have these three core methods implemented: issuing a kernel for execution, allocating memory for inputs/outputs and transmitting buffers to and from the host memory. A format of tensors, which are multi-dimensional arrays (scary right) are implemented to enable optimisers like GPU to GPU transfer and RDMA for memory and communication.
Making Everything Run Smooth
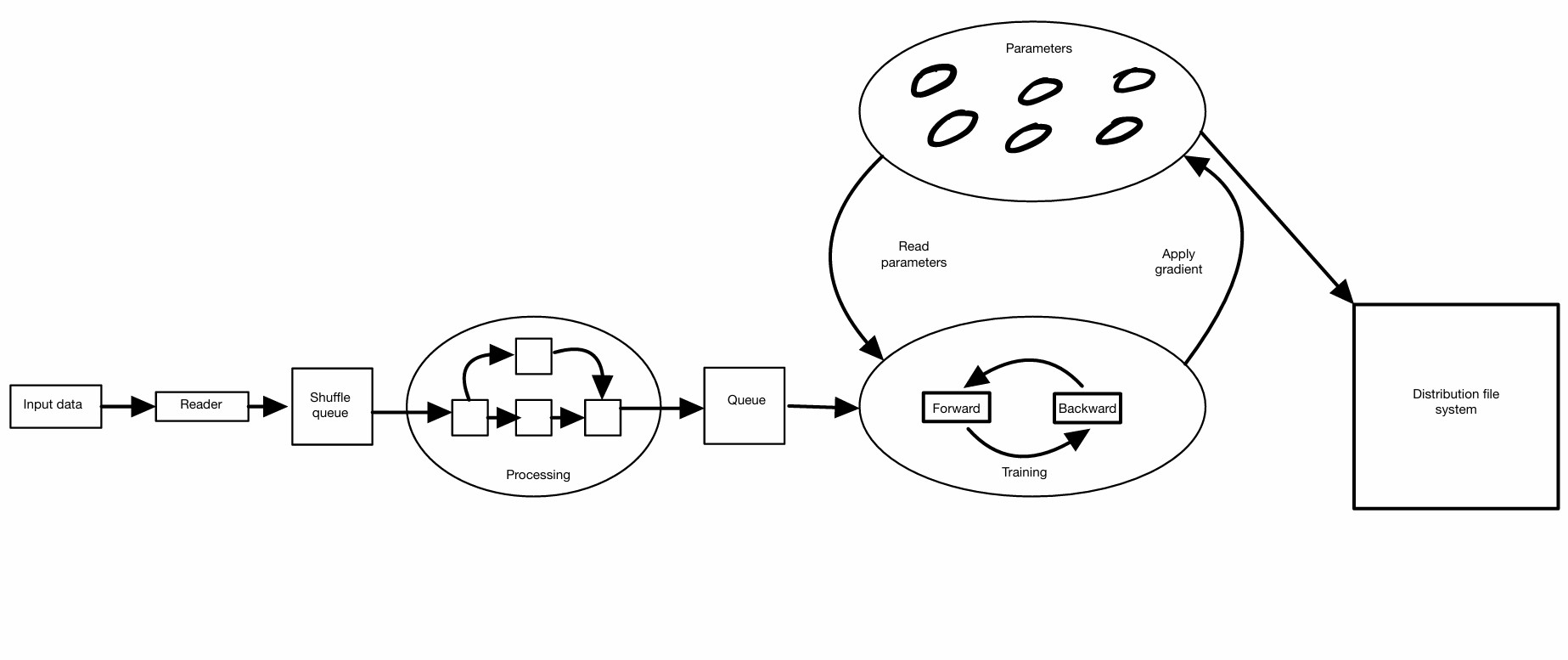
The TensorFlow execution model provided a detailed architecture allowing multiple jobs to be run at once, known as Partial and Concurrent Execution. This architecture involves training being looped, a dataflow graph includes subgraphs for reading data, preprocessing data and the core training loop. Operations such as decoding and preprocessing can run simultaneously and feed data into a queue, ready for training. Furthermore, the subgraphs share mutable data states through parameters and synchronising using queues. An example would be periodic checkpoint tasks that can run alongside training to save its current parameters for fault tolerance.
What Responsibilities Come With This Great Power
Uncle Ben would be happy to hear, the responsibilities (like training large models or fault tolerance) are hard coded into this great power (TensorFlow) all within user-level friendly libraries and primitives. To further justify the change from DistBelief, the Google Brain team put TensorFlow to the test. Putting themselves into the shoes of the researchers and the users.
We will first discuss, differentiation and optimisation, the introduction of a flexible alternative to the DistBelief problem. Take the new user-level library that differentiates a symbolic expression for a loss function, producing a new expression for the loss function. This meant the backpropagation code was now automatically derived. Also, now the model parameters and their updates are represented by nodes on graphs, it became increasingly easier to implement complex optimiser schemes like ADAM or AdaGrad without completely modifying the core system.
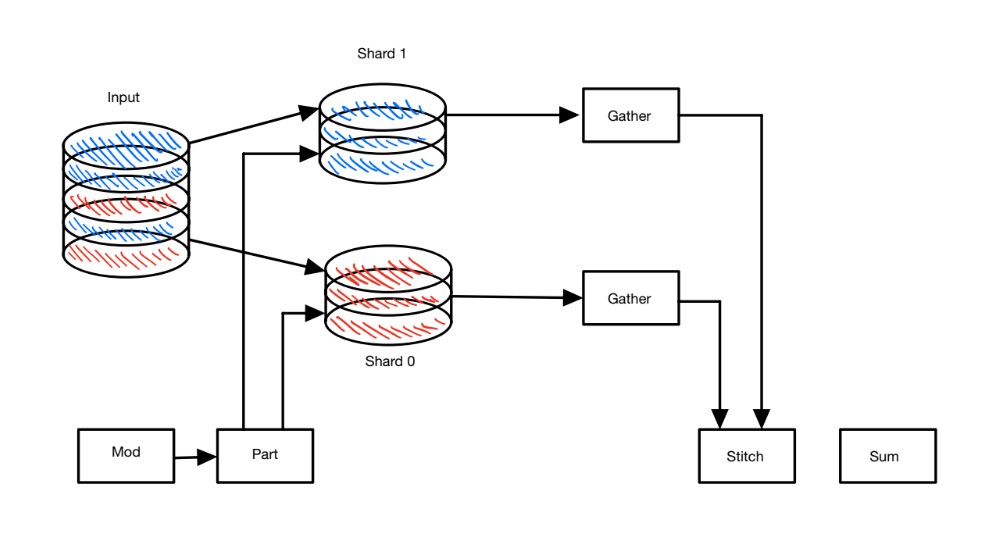
Another job the engineers wanted to tackle was training very large models. TensorFlow addressed this issue by allowing parameters to be sharded (split) across multiple parameter server (PS) tasks. A prime example of how effective TenserFlow is in training these very large models, its “wide and deep learning” framework is used to power Google Play app store recommendations. The model itself can have parameters occupying several terabytes, which requires TensorFlow’s Gather operation to correctly extract the sparse rows needed. Experimenting with sampled softmax is now possible, this can increase the throughput.
Fault tolerance is essential in systems like TensorFlow. TensorFlow will be dealing with a training model for extended periods of time on mostly non dedicated resources. The team implemented thi via checkpointing with operations built into the graph, the save operation and the restore operation. It may seem time consuming to test but because checkpointing is a programmable operation in the graph, users were granted a large degree of freedom and could easily implement forms of transfer learning. Transfer training is simply the end point of the parameters being trained on a task, becomes the startpoint for the next. Very similar to a relay race. This whole programmable operations also lets the user implement custom schemes to fit their liking, which was a massive positive.
While asynchronous training was favoured by the likes of DistBelief, TensorFlow’s primitives allow synchronous replication to be explored by users. The synchronous scheme in its entirety inserted above the core C API, for user level code, using primitives like queues act as a barrier for workers. Previous systems had a problem with straggler workers, slow machines that hold up a whole group. For TensorFlow to mitigate this issue, they use a system of backup workers. This new system was shown to improve throughput in Inception-v3 image classification tasks while simultaneously reducing step time.
Proving the Performance
The proof of performance comes with proving flexibility doesn’t compromise speed. Through extensive evaluation, the Google Brain team confirmed the effectiveness of the system. The outstanding points being: single-machine speed, large scale training and a low overhead. TensorFlow achieved a performance within 6% of Torch (another machine learning framework), on convoluting models while running on a single GPU. To highlight TensorFlows large scale training capabilities, the engineers wanted to test it on Inception-v3 to see its throughput. The final result was Inception-v3’s throughput increasing by 2300 images per second using 200 workers. Overhead can be defined as the time spent doing management work that is not the core computation. TensorFlow and all other frameworks have a duty to get this as low as possible. Microbenchmarks showed the overhead of synchronous coordination had a median step time of only 1.8ms while using small, scalar models
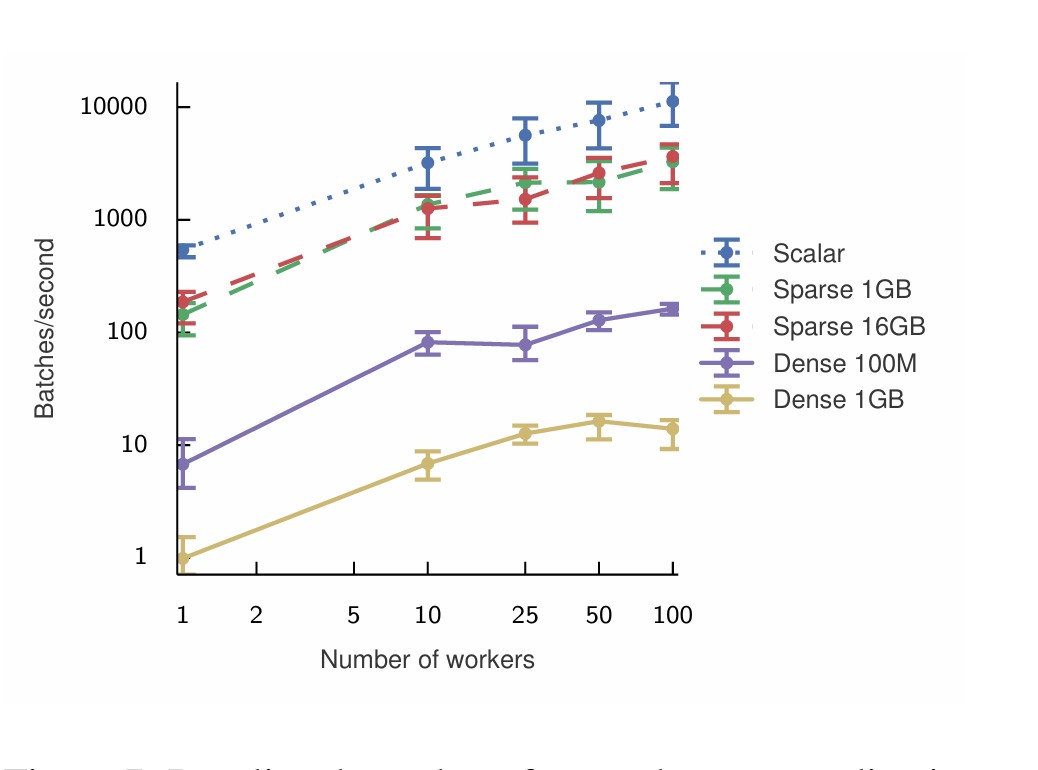
Final Takeaways and My Comments
The engineers at Google Brains built a monster, the success of TensorFlow was no accident. The revolution was born from necessity and planned from start to finish. The core of this paper is that TensorFlow was a far more efficient and optimal replacement for its predecessor DistBelief. Implementing and improving on so much, most notably the use of programmable operation which allowed freedom when altering user-level features.
The author admittedly does mention TensorFlow is a work in progress and still has limitations. The reliance on static dataflow graphs can restrict newer algorithms, especially deep reinforcement learning. This is backed up by the call for further research into automatic placement and optimisation policies to make everything more beginner friendly. So feel free to explore more and make a difference.
Personally I really enjoyed my time exploring this paper. As an Aerospace engineering student looking to explore the world of machine learning, TensorFlow has opened my eyes to how far everything has come. Finally, it’s important to recognise the massive effort by the entire team, including Jianmin Chen, Zhifeng Chen, and Andy Davis, who are among the twenty-two contributors who delivered this foundational system, this report and many other immense contributions to the field.